 Linkedface crawler
Linkedface crawler
Introduction
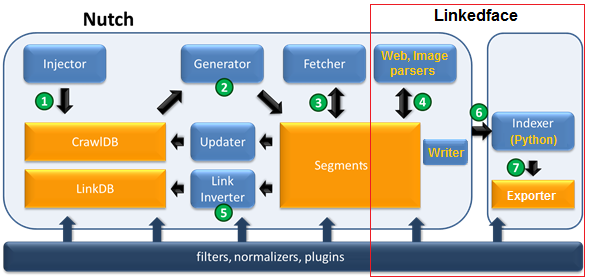
- Linkedface crawler is production, ready-to-use web and image crawler, based on Apache Nutch 2.x. We add some extra-processing into Nutch, make it easy to use.
- User only have to lunch AMI (Amazon Machine Image) in Amazon market place at: https://aws.amazon.com/marketplace/pp/B0727KTRWQ, and then you can have completed crawler solution in your hand. After initiating crawler machine by AMI, you can start crawler immediately by command line or run crontab job and check the result.
- We can offer intelligence processing with face indexing and searching (face detection, face features extraction, and face search) in extension modules.
Environment
- Apache Nutch 2.3
- Hbase: to store raw crawler data
- Python: for data processing
- MySQL server: to store crawled document: webpages and images information
- phpmyadmin: by default, it’s turned off to optimize server performance.
- nginx server: to view crawled image. Default service status is off.
Processing steps
These are processing steps for each round:
- Crawl data: web pages and images
- Remove small images (thumb images, low quality images) and save image into files
- Extract webpage information: publishing date, body text, header information (keywords, description, host, score – page rank)
- Remove duplicate images (in cases, one image can be served in multi – mirror servers)
- Categorize webpages and then images
- Export crawler data: image + mysql data
Running crawler
You can run crawler immediately by one of following methods:
Run by command line:
- reboot crawler server
- run command line:
linkedface number_of_rounds
Run by crontab
- Edit crontab file:
/etc/cron.d/linkedface - Un-comment last two lines and set running schedule:
# /etc/cron.d/linkedface: crontab entries for the linkedface crawler
SHELL=/bin/bash
PATH=/home/ubuntu/bin:/home/ubuntu/.local/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin
MAIL=/var/mail/ubuntu
JAVA_HOME=/usr/lib/jvm/default-java/
LANG=en_US.UTF-8
HOME=/home/ubuntu
SHLVL=2
LANGUAGE=en_US.UTF-8
#40 * * * * ubuntu /home/ubuntu/labsofthings/crawler/bin/hbase_cleaner
#40 * * * * ubuntu /home/ubuntu/labsofthings/crawler/bin/start.sh 3
- Reboot your server, and it will run as schedule
Output data
There are two data:
Database
Webpage document and image information are stored in MySQL database installed locally in crawler server
- DB name: crawler
- Tables: Images and webpages table.
You can view table structure by SQL command line or by phpmyadmin. Data will be exported into sql dump file for each round of crawling. Only data generated in a round is dumped.
Image files
Images are stored in following folders:
├── imgs // For original images
└── thumbs
├── 150 // For generated thumbnail images – width: 150 px
└── 300 // For generated thumbnail images – width: 300 px
All these data will be packaged in to compressed file, and store in folder:
/labsofthings/data/crawler_data/yyyy-MM-dd/
Option configuration
Seed file
All starting urls for crawling are stored in file:
/home/ubuntu/labsofthings/seed/urls.txt
You can add more starting urls here, each url in one line.
Data folder
To crawl large amount of data, you have to store data folder in big storage device. You can do it in these steps:
- Create large AWS storage device ( for example: st1 ) and attach to machine
- Create folders in this device as bellow structure under user
ubuntu:
├── data
│ ├── crawler_data
│ ├── hbase_data
│ └── zookeeper_data
└── nginx_img
- Create soft links:
#: ln -s /labsofthings/data/ data
#: ln -s /labsofthings/nginx_img/ nginx_img
Exporting data
You can copy packaged data file of each crawl round into destionation server by steps:
-
Open file:
/home/ubuntu/labsofthings/indexer/index.sh -
Un-comment line 42 and configure information for destination server:
# Copy data into remote gateway server
#scp -i $key $1.zip $gatewayUser@$gatewayIP:$gatewayFolder/$1.zip
Others
- Remove duplication
- Categorize document
View crawl result
Checking result data is very easy. You need turn on phpMyAdmin and Nginx server to do it.
Note:
- These operations are security risks. They are only for testing and after testing, turn services off.
Nginx
- Stop/start nginx by command:
sudo service nginx start / stop - Access url: http://your_ip:9090
Sample nginx screen:
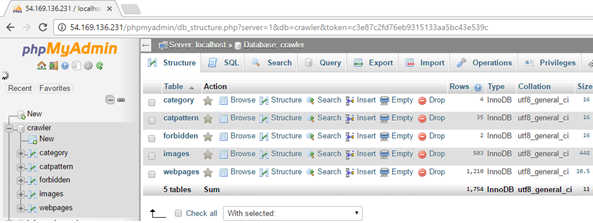
phpmyadmin
Stop/start phpmyadmin by command: sudo service apache2 start / stop
- Access url: http://your_ip/phpmyadmin
- DB name: crawler
- Account: root / lot2016
Sample phpmyadmin screen:
Extension support
- We can offer face detection and face feature extraction in an extension module to help you make face search service.
- Please contact us for more information.
Notable Relevant Projects
- https://linkedface.com: Image news and face search service
Conntact us
You can contact me for more information:
- Name: Thuc X.Vu
- Organization: IoT and Data processing Labs
![]()
- Addess: Toong office, 4th Floor, No. 8 Trang Thi, Hoan Kiem Dist., Hanoi, Vietnam
- Tel: +84 4 3926 3888
- Mobile: +84 912 083 463
- Email: thuc@labsofthings.com
- Website: http://labsofthings.com, or: https://linkedface.com